Para determinar si existe cointegración entre dos series, primero vamos a analizar un modelo estático para las series de precios del USDCOP y WTI. Luego vamos a enriquecer la estimación mediante un modelo dinámico y veremos si es significativo incluir el término de corrección de error para ver si ante grandes cambios de precios hay un retorno rápido al modelo de equilibrio.
Descarguemos los precios.
library(quantmod) # libreria para descargar precios
getFX("USD", src="oanda", from="2008-01-02", to="2016-01-01")
getSymbols("DCOILWTICO", src="FRED")
Existen límites de 5 años para descargar precios de la fuente de datos OANDA. Por lo que es necesario descargar periodos mayores en varias partes. Por ejemplo llamando usd1 a un primer periodo entre 2008 y 2012, y luego usd2 al segundo periodo entre 2012 y 2016. Luego se pueden unir ambas partes para que queden en una sola serie usando la función rbind(). Una vez descargados los datos, realizamos una tabla:
data = na.locf(cbind(rbind(usd1,usd2), DCOILWTICO["2008-01-02::2016-01-01"]))
colnames(data) = c("USDCOP","WTI")
La función na.locf() realiza sustituciones en las fechas donde hay NA's con el precio del día anterior.
cbind() realiza una combinación por columnas (mantiene las fechas para USDCOP y WTI)
rbind() realiza una combinación por filas. (mantiene una columna para diferentes fechas)
El resultado es:
head(data)
USDCOP WTI
2008-01-02 2013.72 97.01
2008-01-03 2015.18 98.45
2008-01-04 2011.58 96.87
2008-01-05 2003.35 96.87
2008-01-06 2006.00 96.87
2008-01-07 2010.96 94.19
Identificando las series
Podemos hacernos una idea de estas dos series, mediante un gráfico de precios relativos (ambas series tienen diferentes escalas de precios y vamos a unirlas en un solo gráfico). Para ello escribimos:
plot(diffinv(as.vector(diff(log(data$USDCOP))),xi=0),
type="l",
col="blue",
main="USD/COP v.s WTI",
ylab="Precios relativos",
xlab="Días",
ylim=c(-1.5,0.6))
lines(diffinv(as.vector(data$WTI),xi=0),col="red")
 La línea de color rojo son los precios relativos del WTI y en azul el USDCOP.
La línea de color rojo son los precios relativos del WTI y en azul el USDCOP.
A simple vista, podemos ver que a grandes caídas de precios del WTI el Peso-Dólar reacciona al alza. Mientras que a precios altos del WTI, la divisa baja.
La función plot() realiza gráficos.
diffinv() hace integración discreta, se propone un precio inicial de cero y va sumando la rentabilidad de cada periodo.
as.vector() en este caso deja sólo el vector de rentabilidades sin sus fechas. otro comando para ésto es coredata().
diff() hace diferenciación discreta, obteniendo el cambio entre dos periodos consecutivos.
log() saca el logaritmo natural de cada precio.
Otra forma de ver la relación inversa entre estas dos series es realizando un gráfico del Dólar versus WTI.

Podemos ver que ante grandes precios del WTI hay bajos precios del USDCOP, y viceversa.

La función lm() estima los coeficientes del modelo. El intercepto es significativo, al igual que el logaritmo del precio de cierre del WTI el mismo día. Si los errores del modelo son I(0) (como veremos a continuación), entonces las dos series están cointegradas mediante un coeficiente de cointegración de -0.3753 y un error estandar residual de 0.07496.
Ahora realizamos el test de ADF. Para ello usaremos el paquete urca, si no lo tienes instalado usa el comando install.packages("urca") y carga la librería mediante el comando library(urca).

plot(diffinv(as.vector(diff(log(data$USDCOP))),xi=0),
type="l",
col="blue",
main="USD/COP v.s WTI",
ylab="Precios relativos",
xlab="Días",
ylim=c(-1.5,0.6))
lines(diffinv(as.vector(data$WTI),xi=0),col="red")
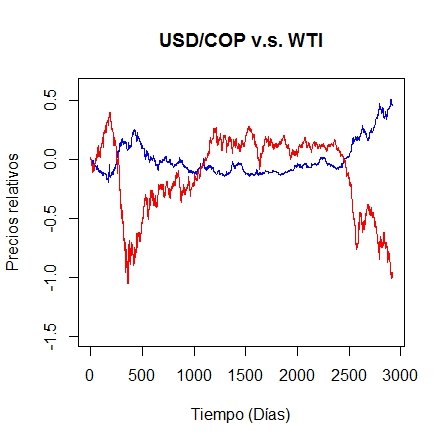
A simple vista, podemos ver que a grandes caídas de precios del WTI el Peso-Dólar reacciona al alza. Mientras que a precios altos del WTI, la divisa baja.
La función plot() realiza gráficos.
diffinv() hace integración discreta, se propone un precio inicial de cero y va sumando la rentabilidad de cada periodo.
as.vector() en este caso deja sólo el vector de rentabilidades sin sus fechas. otro comando para ésto es coredata().
diff() hace diferenciación discreta, obteniendo el cambio entre dos periodos consecutivos.
log() saca el logaritmo natural de cada precio.
Otra forma de ver la relación inversa entre estas dos series es realizando un gráfico del Dólar versus WTI.

Podemos ver que ante grandes precios del WTI hay bajos precios del USDCOP, y viceversa.
Modelo Estático (Equilibrio)
Yt = a + b·Xt + et
Yt~I(1) Xt~I(1) et~I(0)
La pendiente (o parámetro de cointegración) tiene sentido con variables I(1) cointegradas. Ya que de esta manera, el modelo de regresión tiene media constante (relación de largo plazo), varianza constante, autocorrelaciones que dependen sólo del periodo transcurrido entre dos variables y no está correlacionada asintóticamente.
El equilibrio (o relación de largo plazo) ocurre cuando et=0. Si ocurren desviaciones en algún momento, éstas retornarán al equilibrio (la media). Estimaremos el coeficiente de cointegración mediante una regresión y aplicaremos la prueba de Dikey-Fuller Aumentada (ADF) para comprobar estacionariedad.

La función lm() estima los coeficientes del modelo. El intercepto es significativo, al igual que el logaritmo del precio de cierre del WTI el mismo día. Si los errores del modelo son I(0) (como veremos a continuación), entonces las dos series están cointegradas mediante un coeficiente de cointegración de -0.3753 y un error estandar residual de 0.07496.
Ahora realizamos el test de ADF. Para ello usaremos el paquete urca, si no lo tienes instalado usa el comando install.packages("urca") y carga la librería mediante el comando library(urca).

La función residuals() extrae los residuales del modelo lineal estimado.
La función as.xts() convierte los residuales en serie de tiempo en formato fecha.
La función ur.ad() realiza el test ADF. El argumento type acepta una de las tres opciones "trend", "drift" y "none". En el ejercicio, primero se realizó la prueba con tendencia y ésta no era significativa, luego con drift tampoco era significativa y por último con "none". Podemos ver que el valor-p es menor para un nivel de significancia del 1%, por tal motivo se rechaza la hipótesis nula de presencia de raíz unitaria, por lo que se acepta la hipótesis alternativa en que los errores del modelo estático son estacionarios o I(0). En resumen, hemos encontrado dos series que están cointegradas.
Modelos Dinámicos
Series no cointegradas
Si los errores del modelo no fueran estacionarios, suponiendo que fueran I(1), la regresión no muestra nada significativo, no hay relación de largo plazo. La regresión es Espuria. Sin embargo se puede construir un modelo dinámico haciendo una regresión de las primeras diferencias diff(Yt), diff(Xt) e incluir algunos términos de sus rezagos, como por ejemplo el rezago de orden uno de la primera diferencia de Yt: lag(diff(Yt), k=1) o los rezagos de orden uno hasta 5 de la primera diferencia de Yt: lag(diff(Yt), k=c(1:5)). Igualmente para la variable Xt. Lo usual es incluir sólo el primer rezago de la primera diferencia en ambas variables, y verificar si los errores son estacionarios. El modelo adquiere la forma:
△log(Yt) = α₀ + α₁· △log(Yt-₁) + γ₀ · △log(Xt) + γ₁ · △log(Xt-₁)+ et
donde et ~ I(0).
Series cointegradas y modelo de corrección de errores
Cuando Yt y Xt están cointegradas es posible adicionar variables I(0) al modelo dinámico. Por ejemplo una variable I(0) son los errores del modelo estático.
et* = Yt - a - b·Xt = Yt - Yt*
Yt* es el valor estimado
Por lo que en el modelo dinámico podemos incluir ahora los errores del modelo estático rezagados un periodo, para determinar si ante grandes diferencias positivos o negativos de los precios con respecto a su equilibrio, éstos retornan rápidamente a su equilibrio. El modelo ahora adquiere la forma:
△log(Yt) = α₀ + α₁· △log(Yt-₁) + γ₀ · △log(Xt) + γ₁ · △log(Xt-₁)+ δ · et-₁* + et
et-₁* son los errores del modelo estático
et son los errores del modelo dinámico
δ · et-₁* recibe el nombre de término de corrección de error
δ · et-₁* recibe el nombre de término de corrección de error
Vamos a estimar inicialmente un modelo dinámico simple y luego adicionaremos el término de corrección de error:
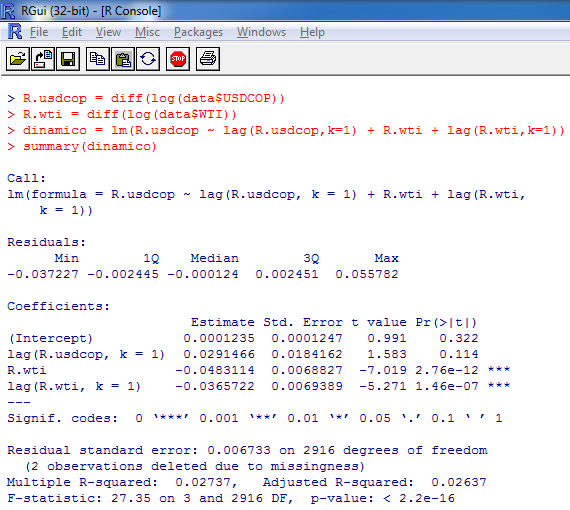
En el modelo observamos que el intercepto no es significativo, y tampoco el rezago de los retornos del usdcop. Por lo que ahora estimaremos nuevamente el modelo sin esos dos términos, eliminando de a una variable y comenzando por la que tiene mayor valor-p (intercepto), luego se verifica las que no sean significativas y se vuelve a eliminar la de mayor valor-p.

La interpretación para el coeficiente de -0.048467 que acompaña el rendimiento WTI, es que ante un cambio de 1% en el rendimiento logarítmico del WTI se espera que el rendimiento logarítmico USDCOP disminuya en 0.048467% manteniendo las demás variables constantes. Éste coeficiente es significativo a cualquier nivel de significancia.
La interpretación para el coeficiente -0.038108 que acompaña al rendimiento del WTI rezagado un periodo, es que ante un cambio del 1% en el rendimiento logarítmico del WTI durante el periodo inmediatamente anterior, se espera que el rendimiento logarítmico del USDCOP disminuya en 0.038108% manteniendo las demás variables constantes. Éste coeficiente es significativo a cualquier nivel de significancia.
Comprobemos si los errores del modelo son I(0):

Recordemos que debemos eliminar un periodo al diferenciar una vez. La prueba se realiza para un nivel de significancia del 1% tanto para una hipótesis de tendencia como para drift. Ambas fueron rechazadas. El valor-p es menor que 1% por lo que se rechaza la hipótesis nula de presencia de raiz unitaria. Entonces los errores del modelo dinámico son I(0).
Ahora vamos a incluir el término de corrección de error y observaremos si éste es significativo en el modelo. Recordemos que para incluir el término, las serires de los precios USDCOP y WTI deben estar cointegradas, así los errores del modelo estático son I(0), lo cual es nuestro caso. Llamaremos a éste, modelo de corrección de errores (ECM)

Vemos que el término de corrección de error no es significativo en el modelo. Por lo tanto nuestro modelo dinámico inicial es el que preferimos.
Hemos visto como detectar si dos series están cointegradas mediante un modelo estático y como realizar un modelo dinámico bien sea que las series están cointegradas o no, incluyendo rezagos de las diferencias y analizando si los errores son I(0). Si las series están cointegradas podemos incluir el término de corrección de error, llamándose Modelo de Corrección de Errores (ECM). Recuerda que cualquier función de R que no entiendas la puedes consultar escribiendo help(nombreFuncion) o ??nombreFuncion.
Hemos visto como detectar si dos series están cointegradas mediante un modelo estático y como realizar un modelo dinámico bien sea que las series están cointegradas o no, incluyendo rezagos de las diferencias y analizando si los errores son I(0). Si las series están cointegradas podemos incluir el término de corrección de error, llamándose Modelo de Corrección de Errores (ECM). Recuerda que cualquier función de R que no entiendas la puedes consultar escribiendo help(nombreFuncion) o ??nombreFuncion.





{kind=link}